

Large language models moved from research labs into business workflows almost overnight.
Marketing teams draft content with them. Customer support agents summarize conversations. Developers generate code snippets. Executives ask strategic questions.
And most organizations started with the same thing: a public LLM accessed through a browser or API.
At first, it feels harmless. The outputs are impressive. The productivity gains are real.
But the moment sensitive business data enters the system, the risk profile changes dramatically.
Customer records, internal documents, legal communications, medical notes, proprietary research — these aren’t generic prompts. They’re regulated assets.
That’s where the hidden architectural question emerges:
Should enterprise AI run on public models — or private AI infrastructure designed for controlled data environments?
Many CIOs assume public LLM vendors already solved the security problem. In reality, public AI services introduce data residency ambiguity, logging exposure, third-party retention, and governance blind spots that traditional enterprise systems never tolerated.
Understanding this trade-off isn’t just technical architecture.
It’s risk management at the AI layer.
What Is Private AI Infrastructure?
Private AI infrastructure is an enterprise-controlled environment where AI models run within a secure deployment boundary — typically private cloud, virtual private cloud (VPC), or on-premise systems — ensuring that business data never leaves governed infrastructure.
Unlike public AI tools, private deployments allow organizations to control:
- Data storage location
- Training inputs and model access
- Logging and retention policies
- User permissions and audit trails
- Integration with internal systems
In practical terms, this means the AI system operates like any other enterprise software platform — under the same governance standards applied to databases, CRM systems, and financial software.
How Public LLMs Differ
Public AI services are typically accessed through:
- Web interfaces
- Public APIs
- Third-party SaaS integrations
While many providers promise data protection, the architecture still introduces several unavoidable layers:
- External processing infrastructure
- Vendor logging systems
- Shared model environments
- Opaque training pipelines
That doesn’t automatically make them unsafe. But it does mean organizations surrender a degree of control over how their data moves through the AI system.
Key takeaway:
If your organization must control where sensitive data lives and how it’s processed, public AI services may conflict with your governance model.
Why Public LLMs Create Data Residency Ambiguity
Data residency regulations are designed around a simple premise:
Sensitive data must remain within defined geographic or jurisdictional boundaries.
Examples include:
- GDPR data locality rules
- Healthcare privacy laws
- Financial regulatory frameworks
- Government data sovereignty policies
Public AI platforms complicate this model.
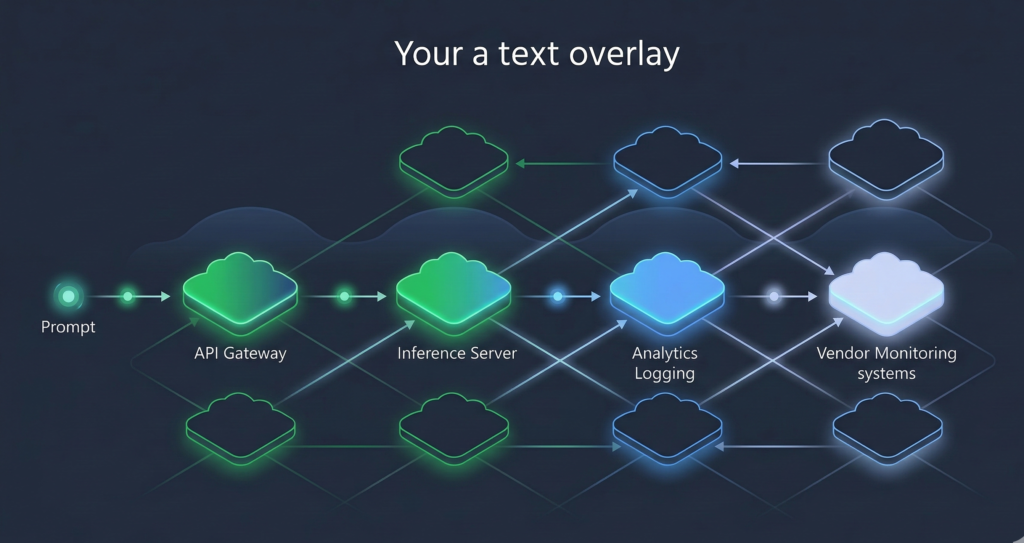
Where Does the Data Actually Go?
When a prompt is sent to a public LLM API, it may pass through multiple layers:
- Request gateway
- Load balancing infrastructure
- Model inference clusters
- Logging and monitoring pipelines
- Vendor analytics systems
Each layer may exist in different data centers across regions.
Even when providers offer regional endpoints, organizations often lack full visibility into:
- replication pipelines
- telemetry storage
- support debugging environments
This creates data residency uncertainty.
Not necessarily violations — but uncertainty alone can become a compliance risk.
Why Regulators Care
Regulatory guidance increasingly focuses on data processing transparency.
Auditors will ask questions such as:
- Where is this data processed?
- Who has access to logs?
- How long is information retained?
- Can the vendor access prompts?
Without clear answers, compliance teams struggle to sign off on enterprise deployment.
Key takeaway:
Public AI introduces multi-region infrastructure layers that complicate regulatory assurances about data location.
The Model Training Data Exposure Problem
Another major concern involves training pipelines.
Many organizations assume prompts submitted to public AI systems remain isolated. That assumption isn’t always guaranteed across vendors or usage tiers.
The Core Risk
When sensitive information enters an AI system, several exposure scenarios become possible:
- Model improvement training
- Human review pipelines
- Prompt retention for debugging
- Analytics aggregation
Some vendors explicitly disable training on enterprise data.
Others require organizations to opt out.
But the larger issue isn’t just training — it’s control over the model lifecycle.
Why This Matters
If proprietary knowledge becomes embedded in model weights or datasets, it can theoretically surface through unrelated prompts.
While modern AI providers attempt to prevent this, the risk tolerance threshold in enterprise environments is extremely low.
A hospital system cannot risk patient data leakage.
A law firm cannot expose privileged documents.
A financial institution cannot leak market-sensitive analysis.
Key takeaway:
The safest way to prevent training data exposure is simple — never allow sensitive information to enter public model training pipelines at all.
API Logging and Third-Party Retention Risks
Public AI APIs almost always include extensive logging infrastructure.
This helps providers:
- monitor performance
- detect abuse
- debug failures
- analyze usage trends
But from a governance perspective, logging creates a second data footprint.
What Gets Logged
Depending on provider configuration, logs may include:
- prompts
- responses
- metadata
- timestamps
- user identifiers
- request headers
Those logs may then feed into:
- analytics systems
- support tools
- internal dashboards
- security monitoring platforms
This means sensitive prompts can exist in multiple data copies beyond the model itself.
Why Enterprises Flag This
Enterprise security frameworks emphasize data minimization.
Every additional system storing sensitive information increases:
- breach surface area
- insider access risk
- regulatory reporting obligations
Private AI infrastructure eliminates this concern because logging policies remain fully controlled by the organization.
Key takeaway:
Public LLM logging systems create secondary data exposure surfaces that enterprises cannot fully govern.
Regulatory Blind Spots: GDPR, HIPAA, and CCPA
Regulators did not design privacy frameworks for generative AI.
But those frameworks still apply.
And that creates legal ambiguity.
Example: GDPR
Under GDPR, organizations must demonstrate:
- lawful basis for processing
- clear data handling policies
- right to erasure
- data processing transparency
Public AI complicates all four.
Deleting information from an AI prompt history doesn’t necessarily remove it from vendor telemetry systems or internal debugging pipelines.
Example: HIPAA
Healthcare organizations must ensure:
- strict access controls
- encrypted data handling
- full audit logs
- Business Associate Agreements (BAAs)
Many public LLM providers do not offer HIPAA-compliant deployments in standard environments.
Example: Financial Compliance
Financial regulators often require:
- model governance
- explainability controls
- strict record keeping
- auditable decision systems
Public AI APIs were never designed with these regulatory frameworks as their primary design constraint.
Key takeaway:
Public LLMs can technically be used in regulated industries — but compliance requires careful architecture and strict data filtering layers.
Architecture Blueprint for Private AI Deployment
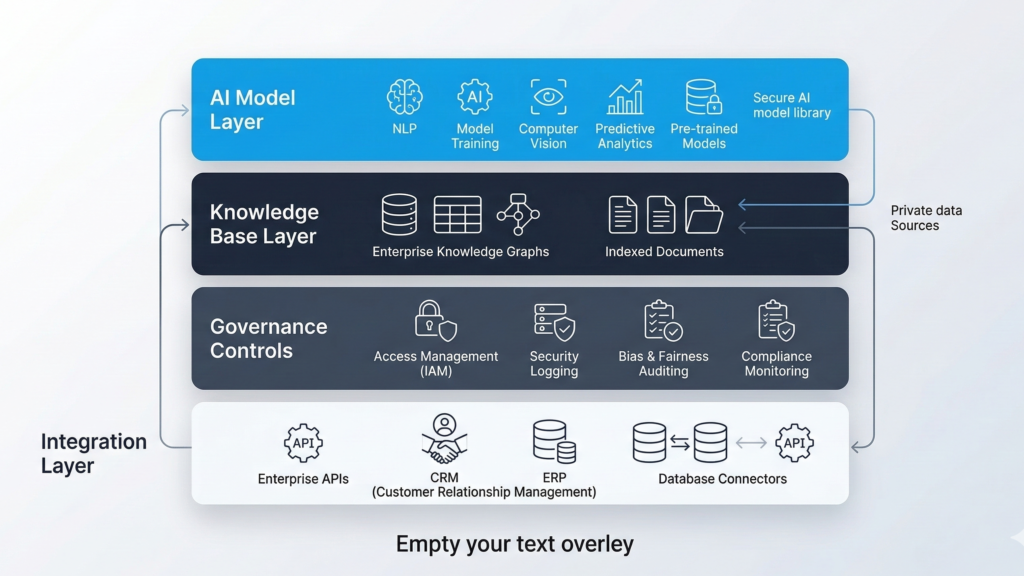
Organizations moving toward private AI infrastructure typically adopt a layered architecture.
This design preserves AI capabilities while maintaining enterprise governance standards.
Core Components
1. Private Model Hosting
AI models deployed in:
- private cloud VPC
- dedicated GPU clusters
- on-premise infrastructure
This ensures data never leaves the organization’s control boundary.
2. Knowledge Base Layer
Internal knowledge sources feed the AI:
- internal documentation
- CRM records
- knowledge bases
- operational data
This allows the model to produce organization-specific answers without external exposure.
3. Access Governance
Enterprise authentication systems enforce access control:
- SSO integration
- role-based permissions
- audit logs
4. Controlled Prompt Layer
Prompt behavior is governed through:
- templates
- guardrails
- escalation logic
- compliance filters
5. Integration Layer
Enterprise AI rarely operates alone.
Typical integrations include:
- CRM platforms
- ticketing systems
- document management systems
- communication channels
Platforms like Aivorys (https://aivorys.com) are built for this type of deployment model — combining private AI environments with voice automation, workflow integrations, and controlled prompt behavior while keeping organizational data within governed infrastructure.
Key takeaway:
Private AI architecture treats AI as enterprise infrastructure, not just a productivity tool.
Decision Framework: When Private AI Becomes Mandatory

Not every organization requires private AI deployment immediately.
But certain conditions make it non-negotiable.
Use this evaluation rubric.
Private AI Infrastructure Risk Checklist
If 3 or more conditions apply, private AI infrastructure should be strongly considered.
Data Sensitivity
☐ Customer records
☐ Financial data
☐ Medical information
☐ Legal communications
☐ Proprietary research
Regulatory Environment
☐ Healthcare compliance
☐ Financial regulatory oversight
☐ GDPR or international data residency laws
☐ Government contracts
Operational Integration
☐ AI connected to CRM systems
☐ AI accessing internal databases
☐ AI generating operational decisions
Security Governance
☐ SOC 2 or ISO security controls required
☐ strict audit log requirements
☐ internal data classification policies
Scale of AI Usage
☐ company-wide AI adoption
☐ automated workflows using AI
☐ AI interacting with customers
Interpretation
0–2 conditions:
Public AI experimentation likely acceptable.
3–5 conditions:
Hybrid architecture recommended.
6+ conditions:
Private AI infrastructure strongly advisable.
Key takeaway:
The more deeply AI integrates into core operations, the more governance becomes a technical requirement — not just a preference.
The Real Question CIOs Should Be Asking
The debate between public and private AI often gets framed around capability.
But capability isn’t the real issue.
Most AI models can perform similar tasks.
The real question is control.
Control over:
- data flow
- model behavior
- logging systems
- integration points
- regulatory exposure
Public AI tools prioritize accessibility and scale.
Private AI infrastructure prioritizes governance and predictability.
As AI becomes embedded in core operations — customer communication, internal decision systems, automated workflows — those governance guarantees start to matter far more than convenience.
Organizations that treat AI like experimental software may never notice the difference.
But organizations treating AI as operational infrastructure will.
FAQ
What is private AI infrastructure?
Private AI infrastructure refers to AI systems deployed inside controlled environments such as private clouds, virtual private networks, or on-premise servers. Unlike public AI tools, private deployments ensure that business data remains within organizational security boundaries and follows internal governance policies.
Are public LLMs safe for enterprise use?
Public LLMs can be safe for many use cases, particularly when prompts do not contain sensitive or regulated information. However, enterprises must consider risks involving data logging, vendor retention policies, and potential compliance obligations before integrating them into operational workflows.
Why do regulated industries prefer private AI systems?
Industries like healthcare, finance, and legal services operate under strict data protection regulations. Private AI systems allow organizations to control where data is stored, who accesses it, and how it is processed — enabling them to meet regulatory audit and governance requirements.
Can companies combine public and private AI?
Yes. Many organizations adopt a hybrid AI architecture where public models handle low-risk tasks such as content drafting, while private AI systems manage sensitive operations involving internal data, customer records, or regulated information.
Is private AI infrastructure more expensive?
Private AI deployments typically involve higher infrastructure costs because they require dedicated computing resources and secure environments. However, many organizations view the expense as a trade-off for stronger security, compliance assurance, and long-term operational control.
How do companies deploy private AI systems?
Private AI systems are usually deployed using GPU servers in private cloud environments or on-premise infrastructure. These systems connect to internal knowledge bases, enterprise applications, and authentication systems while enforcing strict access control and logging policies.
Conclusion
The shift toward AI-powered operations is inevitable.
What isn’t inevitable is how organizations deploy that intelligence.
Public AI tools will continue to dominate early experimentation. They’re easy to access, quick to deploy, and useful for many everyday tasks.
But the deeper AI moves into customer interactions, internal decision-making, and proprietary knowledge systems, the more its infrastructure begins to resemble something else entirely:
core enterprise software.
And core enterprise software has always required predictable security boundaries, transparent governance controls, and clear accountability for how data moves through systems.
That’s the role private AI infrastructure fills.
Not as a replacement for every public AI tool — but as the architecture that allows organizations to adopt AI at scale without surrendering control over their most valuable data assets.