
The Compliance Risk Nobody Talks About in AI Deployments (GDPR, HIPAA & SOC 2 Gaps) – Copy

Most AI failures in business environments don’t originate in the model. They originate in compliance architecture. An organization deploys a generative AI tool to summarize customer tickets, automate intake forms, or assist with internal decision-making. It works well. Productivity increases. But months later, the compliance team discovers something unsettling. Customer data is being sent to external inference APIs.Sensitive prompts are logged in vendor analytics systems.There’s no clear audit trail showing who asked the AI what, when, and why. Suddenly, the conversation shifts from innovation to liability. AI compliance risk rarely appears during the pilot phase. It appears during the audit. Regulatory frameworks such as GDPR, HIPAA, and SOC 2 were not written for generative AI systems — yet organizations must still demonstrate data control, auditability, and responsible processing when AI becomes part of their operational stack. The uncomfortable truth: most AI deployments treat compliance as a post-implementation concern. By the time governance controls are added, the architecture already exposes risk. This article breaks down where AI compliance failures originate, why common deployments violate regulatory expectations, and how to design compliance-first AI systems from day one. Where AI Compliance Failures Actually Begin When compliance issues emerge in AI deployments, leadership often assumes the technology failed. In reality, the root cause is usually architectural. Most organizations introduce AI in three predictable stages: The compliance problems appear during stage three. The “Shadow AI” Phase During experimentation, teams begin using AI tools independently: These tools are often accessed through browser interfaces or APIs outside the organization’s governance framework. No central approval.No security review.No compliance documentation. This phenomenon is sometimes called shadow AI. It mirrors the early days of shadow IT — except the risk profile is higher because AI processes sensitive information directly through prompts. Why Compliance Teams Discover Problems Late Compliance officers typically audit: AI prompts, however, behave differently. They can contain customer data, personal identifiers, health information, legal documents, or financial analysis — all embedded inside natural language requests. If prompt flows aren’t mapped early, they become invisible compliance exposure points. Key insight:AI compliance risk emerges when AI is treated as a tool instead of a governed system. AI Data Mapping and Classification Pitfalls Every compliance framework ultimately comes down to one core question: Where does sensitive data go? In traditional software architecture, that question is easier to answer because data moves through defined pipelines. AI changes the dynamic. The Prompt as a Data Container Prompts can contain: This means a single prompt can unintentionally contain multiple regulated data types simultaneously. For example: A healthcare intake assistant might send prompts containing: If that prompt travels to an external AI provider without a HIPAA-compliant processing agreement, the organization may already be out of compliance. The Classification Failure Most companies maintain data classification policies such as: But AI prompts rarely pass through classification filters. Employees paste information directly into AI tools. No automatic tagging.No policy enforcement. What Mature Organizations Do Instead Organizations that successfully manage AI compliance risk implement prompt-aware data governance. Typical controls include: Actionable takeaway:Before deploying AI broadly, map every data category that could appear in prompts — not just structured datasets. Why AI Systems Require Full Audit Trails Traditional software logs transactions. AI systems must log decisions and reasoning inputs. This distinction matters for compliance. What Regulators Expect Across frameworks like GDPR, HIPAA, and SOC 2, regulatory guidance increasingly emphasizes traceability. Organizations must demonstrate: With AI systems, that means capturing: The Audit Gap Most Companies Miss Many AI integrations capture only API request logs. That is insufficient. A proper AI audit trail should include: User Context Prompt Context Model Output System Actions Without these logs, organizations cannot reconstruct how an AI-driven decision occurred. In regulated industries, that becomes a major governance gap. Key insight:If you cannot reconstruct the AI decision process, auditors will treat the system as uncontrolled automation. Vendor Risk Management in AI Stacks AI systems rarely exist in isolation. They typically involve multiple vendors: Each layer introduces potential compliance exposure. The Vendor Stack Problem A typical AI workflow might look like this: Each vendor may process sensitive data. But most organizations only evaluate one of them — the model provider. Vendor Due Diligence Questions Compliance teams should ask: Industry consensus among compliance practitioners suggests that AI vendor risk reviews must extend to the entire orchestration stack, not just the model. Where Governance Starts to Matter Organizations deploying private AI environments gain control over: Platforms like Aivorys (https://aivorys.com) are designed for this governance layer — private AI environments with controlled data handling, voice automation, and CRM-connected workflows that keep sensitive operational data inside governed infrastructure. Actionable takeaway:Treat AI deployments like supply chains — every vendor in the pipeline must pass compliance scrutiny. The AI Governance Gap in Most Organizations Many companies assume governance begins after deployment. That assumption creates risk. Governance Should Exist Before the First Prompt A compliance-ready AI program typically defines: Policy Architecture Monitoring The Cultural Challenge Technology controls alone aren’t enough. Organizations must train employees to understand: This is similar to security awareness training — except the focus is data exposure through prompts. Key insight:AI governance is not a document. It is a system of architecture, monitoring, and policy enforcement. The Compliance-First AI Architecture Framework Organizations deploying AI responsibly design governance into the architecture itself. The following framework is used by many enterprise security teams evaluating AI systems. The 5-Layer Compliance AI Framework 1. Data Classification Layer Define what information AI systems can access. Controls include: 2. AI Processing Layer Determine where inference occurs: Sensitive workloads should never default to public inference endpoints. 3. Identity and Access Layer AI access must follow the same controls as other enterprise systems: 4. Audit and Monitoring Layer Capture complete interaction records: 5. Governance and Policy Layer Define rules governing AI behavior: Quick Compliance Readiness Checklist Use this 10-point rubric to evaluate your AI environment. Score 1 point for each “Yes.” Score Interpretation 8–10 → Compliance-ready architecture5–7 → Moderate risk0–4 → High compliance exposure Actionable takeaway:Compliance readiness depends far more
AI Liability in 2026: Who Is Responsible When Your AI Makes a Mistake?
An AI system denies a loan application incorrectly. A chatbot provides inaccurate medical intake advice. An automated sales assistant sends misleading information to a customer. None of these failures require malicious intent. They can emerge from training data bias, automation logic errors, prompt manipulation, or system integration issues. The real problem is what happens next. Who is responsible when AI makes a mistake? The vendor that built the system?The company that deployed it?The employee who relied on the output? This question sits at the center of a rapidly evolving legal issue: AI liability for businesses. As organizations deploy AI across customer service, sales, operations, and decision support, legal frameworks are still catching up. Regulators are issuing guidance, but clear global standards remain uneven. That uncertainty creates a new category of operational risk. AI can automate decisions at scale — but without governance structures, accountability becomes unclear when those decisions cause harm. For CEOs and legal leaders evaluating AI adoption, the real challenge is not whether AI can create value. It’s whether the organization can deploy it responsibly enough to withstand regulatory scrutiny and legal disputes. This article examines how AI liability works in practice, how responsibility is typically distributed across vendors and enterprises, and what governance frameworks businesses need to reduce legal exposure. What Is AI Liability for Businesses? AI liability for businesses refers to the legal responsibility organizations may face when an artificial intelligence system causes harm, makes incorrect decisions, or violates regulations during business operations. Liability may arise in several contexts: When an AI system produces an outcome that leads to harm, regulators and courts typically evaluate three questions: AI does not eliminate accountability. In most legal interpretations, organizations remain responsible for the tools they deploy, even when those tools rely on external vendors or automated models. Why AI Liability Is Increasingly Relevant Three trends are accelerating legal scrutiny: 1. Automation of business decisions AI increasingly participates in operational choices previously made by humans. 2. Scale of impact Automated systems can affect thousands of customers simultaneously. 3. Regulatory momentum Governments worldwide are developing frameworks addressing AI accountability and transparency. Micro-insight:AI mistakes are rarely technical failures alone — they become legal issues when governance is absent. Actionable takeaway:Before deploying AI in customer-facing or decision-support roles, organizations must define who is accountable for monitoring outputs and intervening when errors occur. AI Decision Accountability: Who Owns the Outcome? A common misconception is that AI decisions are autonomous. In reality, AI systems operate within organizational control structures. That means responsibility ultimately maps back to the organization deploying the technology. The Four Layers of AI Accountability Understanding liability requires examining four operational layers. 1. Model Developer The organization that builds the underlying AI model. Responsibilities may include: However, most developers disclaim liability for how the model is used downstream. 2. AI Platform Provider The company offering the infrastructure or system integrating the model. Responsibilities may include: 3. Deploying Organization The business implementing the AI system within its workflows. Responsibilities typically include: This layer carries the majority of legal accountability. 4. Human Oversight Employees responsible for reviewing or acting on AI outputs. Courts and regulators increasingly expect human oversight in high-risk AI applications. Micro-insight:AI does not replace responsibility — it redistributes it across system layers. Actionable takeaway:Every AI deployment should include a documented accountability chain identifying who owns monitoring, escalation, and corrective action. Vendor vs. Enterprise Liability: Where Responsibility Actually Falls When AI errors occur, organizations often assume the vendor bears the risk. In practice, liability usually shifts toward the deploying business. Why Vendors Limit Legal Responsibility Most AI platform agreements include clauses that: This reflects a fundamental legal principle: Vendors provide tools — businesses control how those tools are used. Example Scenario Consider a sales automation AI that sends inaccurate pricing information. Possible liability paths: Scenario Responsible Party Vendor algorithm malfunction Vendor partially responsible Business configured incorrect pricing rules Business responsible AI misinterprets prompt instructions Business responsible Employee ignores warning signals Business responsible Most disputes ultimately hinge on whether the deploying company implemented reasonable safeguards. What Courts Typically Evaluate Legal analysis usually focuses on: Micro-insight:The more autonomy you give AI systems, the more governance you must demonstrate. Actionable takeaway:Legal teams should review AI vendor contracts carefully to understand liability limits and operational responsibilities. Emerging Regulatory Guidance for Enterprise AI Regulatory bodies around the world are actively shaping AI governance frameworks. While laws differ by jurisdiction, several common principles are emerging. Core Regulatory Themes Across regulatory guidance and policy discussions, several expectations consistently appear. Transparency Organizations should disclose when AI participates in decision-making processes. Accountability Businesses must assign responsibility for AI outcomes. Risk classification High-impact AI use cases require stronger oversight. Examples include: Auditability Organizations must maintain documentation showing how AI decisions are generated. Risk-Based Regulation Many regulatory proposals use a risk-tier model. Risk Level Example AI Use Case Oversight Requirement Low internal productivity tools minimal Medium marketing automation moderate High credit scoring or hiring strict Industry consensus:Organizations deploying high-risk AI must demonstrate active governance and oversight. Actionable takeaway:Classify AI deployments by risk level before implementation. High-impact use cases require formal governance processes. AI Documentation Requirements: The Evidence of Responsible Deployment When disputes occur, documentation often determines legal outcomes. Organizations must prove they implemented AI responsibly. Critical Documentation Categories Legal and compliance teams should maintain records across five areas. 1. Use Case Definition Clear description of: 2. Risk Assessment Documentation evaluating potential harms such as: 3. Model Limitations Understanding where the AI system may fail. 4. Monitoring Procedures Policies describing: 5. Incident Response Plan Defined procedures for handling AI errors or unexpected behavior. Platforms like Aivorys (https://aivorys.com) address part of this challenge by supporting controlled deployments, audit logging, and workflow guardrails around enterprise AI systems — capabilities that become increasingly important as governance expectations grow. Micro-insight:Good documentation doesn’t prevent AI mistakes — it proves you managed risk responsibly. Actionable takeaway:Create an internal AI deployment record for every system used in customer-facing or decision-making roles. Risk Mitigation Framework for AI Liability Organizations can significantly
Your AI Assistant Is Logging More Data Than You Think: Hidden Exposure Risks

AI systems appear deceptively simple from the user interface: type a prompt, receive a response. But beneath that interaction sits a complex telemetry layer recording prompts, responses, metadata, and operational signals. For many organizations, that hidden infrastructure introduces serious AI data logging risks. Prompts may contain internal documents. Responses may reference proprietary information. API requests often include identifiers, timestamps, and behavioral signals. And in many AI platforms, those records are automatically stored in logs that engineering teams rarely audit. The result is a quiet accumulation of sensitive information across logging pipelines, monitoring dashboards, and third-party analytics tools. The risk rarely appears during the pilot phase. It emerges months later—during a compliance review, internal security audit, or breach investigation—when teams discover that their AI assistant has been recording far more operational data than expected. This article examines the most common categories of AI logging exposure, why they often go unnoticed, and how technical leaders can implement controlled audit trails without sacrificing observability. The AI Logging Layer Most Teams Forget Exists Most AI discussions focus on models, prompts, and outputs. Very few address the logging layer that surrounds them. Yet modern AI systems generate multiple classes of logs automatically: Each of these can contain sensitive information. Prompt and Response Logging Many AI platforms record prompts and responses to support: That means the following may be stored automatically: Even if the AI system itself is secure, logged prompts may create an entirely separate data exposure surface. Observability Platforms Multiply the Exposure Logs rarely stay in one place. Engineering teams commonly route them through: Each additional system increases the attack surface. The AI model may be secure—but its logs may exist across half a dozen systems. Takeaway:Before approving enterprise AI deployments, CTOs should audit not only the model provider but also the entire logging and monitoring pipeline surrounding it. API Request Metadata: The Silent Data Leak One of the least understood sources of AI data logging risks is API metadata. Even when prompt content is removed, API requests often log contextual data such as: Individually these fields seem harmless. Combined, they create a detailed behavioral record. Why Metadata Matters Metadata can reveal: This information can be valuable for monitoring—but it also creates compliance exposure. In regulated industries, metadata can qualify as sensitive operational data. A Common Scenario Consider a healthcare scheduling assistant: Even if patient names are removed, logs might record: Those fields may still fall under regulatory data protection frameworks. Takeaway:Enterprise AI monitoring should treat metadata as sensitive operational data, not harmless system noise. The Retraining Trap: When Logs Become Training Data Many organizations assume logs are temporary records. In practice, they often become something else: training datasets. AI vendors frequently collect prompt and response logs to improve model performance. This process can create unexpected exposure. The Mechanism Typical workflow: If those logs contain proprietary content, they may enter training pipelines. Why This Creates Risk Several concerns emerge: For enterprises, this raises governance questions about data residency, retention, and model ownership. Platforms built for enterprise deployments increasingly separate operational logging from model improvement pipelines to prevent this risk. Platforms like Aivorys (https://aivorys.com) are built for this exact use case — private AI with controlled data handling, voice automation, and CRM-connected workflows where operational data remains inside the organization’s controlled environment. Takeaway:Always verify whether your AI vendor uses prompt logs for training—and whether opt-out controls actually isolate your data. Third-Party Logging Tools Multiply Exposure Logging rarely happens inside the AI platform alone. Most engineering stacks send logs to external infrastructure such as: These integrations are useful—but they create additional data flows. A Typical Enterprise Logging Pipeline A single AI interaction may produce logs that travel through: Each stage may store copies of the data. The Hidden Problem Security reviews often focus on the AI vendor. But third-party logging tools may store more data than the AI provider itself. These tools may also retain logs for months or years depending on configuration. Takeaway:AI risk reviews must map the entire log lifecycle—not just the AI system. The AI Logging Audit Checklist CTOs Should Run Most organizations have never performed a structured AI logging audit. A simple framework can quickly identify exposure risks. AI Logging Risk Assessment Checklist Evaluate your AI system across five categories. 1. Prompt Logging 2. Response Storage 3. Metadata Collection 4. Third-Party Log Routing 5. Model Training Exposure Score each category: Risk Level Criteria Low Minimal logging, strict retention, isolated datasets Medium Logs retained but controlled and audited High Prompt logging + third-party storage + unclear retention Takeaway:Most enterprises discover their highest exposure risk not in the AI model itself—but in the surrounding logging ecosystem. Designing Controlled AI Audit Trails AI systems still require logging. Without it, teams lose visibility into performance, errors, and misuse. The goal is not eliminating logs—it’s controlling them. Principles of Secure AI Audit Logging 1. Data Minimization Log only what is necessary for system monitoring. Remove: 2. Structured Logging Policies Define explicit rules: 3. Segregated Storage Separate: This prevents cross-contamination. 4. Encryption and Access Controls Logs should be protected like any sensitive dataset. Use: Takeaway:AI logging must be treated as a security system—not merely a developer convenience. Data Minimization: The Most Effective Risk Reduction Strategy The most reliable way to reduce AI data logging risks is straightforward: collect less data. This principle appears consistently in security frameworks and regulatory guidance. Practical Implementation Methods Prompt Redaction Automatically remove: before logs are stored. Tokenized Identifiers Instead of storing user data directly, store anonymized tokens that map to internal records. Log Sampling Not every interaction needs to be recorded. Sampling reduces storage exposure while preserving observability. Short Retention Windows Many AI logs do not require long-term storage. Retention policies of: dramatically reduce breach exposure. Takeaway:Reducing log volume is often more effective than trying to secure massive datasets after they already exist. The Future of Enterprise AI Monitoring The first wave of AI adoption focused on capability. The next wave will focus on governance. As AI becomes embedded in customer support,
How Secure Voice AI Systems Protect Customer Conversations from Data Leakage

Voice AI has moved rapidly from novelty to operational infrastructure. Enterprises now rely on conversational systems to handle customer calls, intake requests, qualify leads, schedule appointments, and automate service workflows. Every one of those interactions contains sensitive information: personal data, financial details, healthcare questions, contract discussions, internal operations. For IT security leaders, that raises a critical question. Where does all that conversation data actually go? Many voice AI deployments prioritize natural-sounding speech and automation features while overlooking the deeper architecture required to protect the conversations themselves. If voice pipelines are poorly secured, sensitive information can leak through logging systems, model training pipelines, analytics platforms, or shared infrastructure. Secure voice AI systems solve this problem by treating conversations as protected data flows rather than simple audio streams. This means applying the same rigor used for enterprise infrastructure: Understanding these mechanisms is essential before deploying conversational AI at scale. Security is not a feature layered on top of voice automation. It is the architectural foundation that determines whether the system is safe to use at all. Where Voice AI Data Is Most Vulnerable Most enterprise security reviews start with the obvious risk: recorded phone calls. That’s only part of the picture. Voice AI systems process conversation data through multiple stages, and each stage introduces a different potential exposure point. 1. Audio Transmission The first vulnerability appears the moment a call begins. Audio streams travel between telephony infrastructure and AI processing systems. If these pipelines are not encrypted end-to-end, attackers could theoretically intercept raw voice data. This is especially concerning for industries handling: 2. Speech Transcription Pipelines Voice AI systems convert audio into text so natural language models can analyze it. If transcription services run on shared infrastructure or public APIs, conversation data may pass through external processing environments. This is where many deployments unknowingly introduce data exposure. 3. Conversation Logging and Analytics Operational analytics often store transcripts for later analysis. Without strict controls, these logs can contain: If logging systems lack role-based access or encryption, they become attractive targets for attackers. 4. Model Training Pipelines Some conversational AI systems improve by training on collected conversations. While this can enhance performance, it also raises major governance questions: Practitioner insight: many organizations focus on the voice interface while ignoring the downstream systems processing the conversation. Security takeaway: A secure deployment must protect every stage of the voice data lifecycle, not just the call itself. Encryption Standards Behind Encrypted AI Calls Encryption forms the backbone of secure voice AI systems. Without strong cryptographic protections, voice pipelines become vulnerable to interception or unauthorized access. Transport Encryption During a call, voice data moves between several components: Transport encryption protects these connections. Most enterprise deployments rely on: These protocols ensure that intercepted data remains unreadable without encryption keys. Storage Encryption Once conversations are processed, they may be stored for operational analysis or compliance purposes. Secure systems encrypt stored data using standards such as: Encryption keys should be managed through dedicated key management systems rather than embedded within application code. Key Management and Access Controls Encryption alone is not sufficient. Organizations must control who can decrypt conversation data. Secure architectures typically enforce: Security takeaway: encrypted AI calls require both cryptography and disciplined key governance. One without the other leaves gaps. Data Storage and Retention Policies for Voice AI Even with encryption, storing conversations indefinitely creates risk. Enterprise security policies usually define strict rules governing how long customer communications can be retained. Voice AI deployments should follow similar practices. Why Retention Policies Matter Recorded calls and transcripts accumulate rapidly. A company processing thousands of daily calls can generate millions of lines of conversational data each month. If this information remains indefinitely accessible, it increases exposure in the event of a breach. Common Enterprise Retention Models Security teams typically implement one of three models. Short-term operational retention Transcripts stored temporarily for operational analytics. Typical window: 7 to 30 days Compliance retention Certain industries must preserve communication records for regulatory purposes. Examples include finance or insurance. Selective archival Sensitive conversations may be deleted automatically while operational metrics are retained in aggregated form. Governance Controls Retention policies should be enforced through automated controls rather than manual processes. Key safeguards include: Security takeaway: Retention policies limit the blast radius of a potential breach by reducing the volume of stored conversational data. Private Hosting vs Shared AI Infrastructure Infrastructure architecture has a major impact on voice AI security. Many early conversational systems relied heavily on shared cloud infrastructure and external APIs. While convenient, this architecture can create exposure for sensitive enterprise data. Shared AI Infrastructure In shared environments: These setups can be acceptable for low-risk use cases but may violate compliance requirements in regulated industries. Private AI Infrastructure Private deployments isolate conversational systems within controlled environments. Options include: This architecture ensures that: Platforms like Aivorys (https://aivorys.com) are designed around this model, allowing organizations to deploy private voice AI with controlled data handling, workflow automation, and internal integrations while maintaining strict governance over conversational data. Security takeaway: Infrastructure isolation is one of the strongest safeguards against data leakage in conversational AI systems. Compliance Requirements for AI Call Infrastructure Organizations operating in regulated sectors must ensure voice AI deployments align with industry compliance frameworks. While requirements vary, most share similar principles around data protection and access control. Healthcare Healthcare systems handling patient communications must align with HIPAA safeguards. Key considerations include: Financial Services Financial institutions must often meet regulatory expectations related to customer data protection and recordkeeping. This may include: Legal and Professional Services Professional services organizations must protect confidential client information. Voice AI deployments should enforce strict confidentiality controls and data governance policies. Practitioner insight: Compliance requirements often focus on governance and auditability rather than specific technologies. Security takeaway: voice AI deployments must map technical controls directly to the regulatory frameworks governing customer communications. Security Evaluation Checklist for Secure Voice AI Systems Security leaders evaluating conversational platforms should apply a structured assessment rather than relying on vendor claims. The Enterprise Voice AI Security Checklist Score
The Compliance Risk Nobody Talks About in AI Deployments (GDPR, HIPAA & SOC 2 Gaps)

Most AI failures in business environments don’t originate in the model. They originate in compliance architecture. An organization deploys a generative AI tool to summarize customer tickets, automate intake forms, or assist with internal decision-making. It works well. Productivity increases. But months later, the compliance team discovers something unsettling. Customer data is being sent to external inference APIs.Sensitive prompts are logged in vendor analytics systems.There’s no clear audit trail showing who asked the AI what, when, and why. Suddenly, the conversation shifts from innovation to liability. AI compliance risk rarely appears during the pilot phase. It appears during the audit. Regulatory frameworks such as GDPR, HIPAA, and SOC 2 were not written for generative AI systems — yet organizations must still demonstrate data control, auditability, and responsible processing when AI becomes part of their operational stack. The uncomfortable truth: most AI deployments treat compliance as a post-implementation concern. By the time governance controls are added, the architecture already exposes risk. This article breaks down where AI compliance failures originate, why common deployments violate regulatory expectations, and how to design compliance-first AI systems from day one. Where AI Compliance Failures Actually Begin When compliance issues emerge in AI deployments, leadership often assumes the technology failed. In reality, the root cause is usually architectural. Most organizations introduce AI in three predictable stages: The compliance problems appear during stage three. The “Shadow AI” Phase During experimentation, teams begin using AI tools independently: These tools are often accessed through browser interfaces or APIs outside the organization’s governance framework. No central approval.No security review.No compliance documentation. This phenomenon is sometimes called shadow AI. It mirrors the early days of shadow IT — except the risk profile is higher because AI processes sensitive information directly through prompts. Why Compliance Teams Discover Problems Late Compliance officers typically audit: AI prompts, however, behave differently. They can contain customer data, personal identifiers, health information, legal documents, or financial analysis — all embedded inside natural language requests. If prompt flows aren’t mapped early, they become invisible compliance exposure points. Key insight:AI compliance risk emerges when AI is treated as a tool instead of a governed system. AI Data Mapping and Classification Pitfalls Every compliance framework ultimately comes down to one core question: Where does sensitive data go? In traditional software architecture, that question is easier to answer because data moves through defined pipelines. AI changes the dynamic. The Prompt as a Data Container Prompts can contain: This means a single prompt can unintentionally contain multiple regulated data types simultaneously. For example: A healthcare intake assistant might send prompts containing: If that prompt travels to an external AI provider without a HIPAA-compliant processing agreement, the organization may already be out of compliance. The Classification Failure Most companies maintain data classification policies such as: But AI prompts rarely pass through classification filters. Employees paste information directly into AI tools. No automatic tagging.No policy enforcement. What Mature Organizations Do Instead Organizations that successfully manage AI compliance risk implement prompt-aware data governance. Typical controls include: Actionable takeaway:Before deploying AI broadly, map every data category that could appear in prompts — not just structured datasets. Why AI Systems Require Full Audit Trails Traditional software logs transactions. AI systems must log decisions and reasoning inputs. This distinction matters for compliance. What Regulators Expect Across frameworks like GDPR, HIPAA, and SOC 2, regulatory guidance increasingly emphasizes traceability. Organizations must demonstrate: With AI systems, that means capturing: The Audit Gap Most Companies Miss Many AI integrations capture only API request logs. That is insufficient. A proper AI audit trail should include: User Context Prompt Context Model Output System Actions Without these logs, organizations cannot reconstruct how an AI-driven decision occurred. In regulated industries, that becomes a major governance gap. Key insight:If you cannot reconstruct the AI decision process, auditors will treat the system as uncontrolled automation. Vendor Risk Management in AI Stacks AI systems rarely exist in isolation. They typically involve multiple vendors: Each layer introduces potential compliance exposure. The Vendor Stack Problem A typical AI workflow might look like this: Each vendor may process sensitive data. But most organizations only evaluate one of them — the model provider. Vendor Due Diligence Questions Compliance teams should ask: Industry consensus among compliance practitioners suggests that AI vendor risk reviews must extend to the entire orchestration stack, not just the model. Where Governance Starts to Matter Organizations deploying private AI environments gain control over: Platforms like Aivorys (https://aivorys.com) are designed for this governance layer — private AI environments with controlled data handling, voice automation, and CRM-connected workflows that keep sensitive operational data inside governed infrastructure. Actionable takeaway:Treat AI deployments like supply chains — every vendor in the pipeline must pass compliance scrutiny. The AI Governance Gap in Most Organizations Many companies assume governance begins after deployment. That assumption creates risk. Governance Should Exist Before the First Prompt A compliance-ready AI program typically defines: Policy Architecture Monitoring The Cultural Challenge Technology controls alone aren’t enough. Organizations must train employees to understand: This is similar to security awareness training — except the focus is data exposure through prompts. Key insight:AI governance is not a document. It is a system of architecture, monitoring, and policy enforcement. The Compliance-First AI Architecture Framework Organizations deploying AI responsibly design governance into the architecture itself. The following framework is used by many enterprise security teams evaluating AI systems. The 5-Layer Compliance AI Framework 1. Data Classification Layer Define what information AI systems can access. Controls include: 2. AI Processing Layer Determine where inference occurs: Sensitive workloads should never default to public inference endpoints. 3. Identity and Access Layer AI access must follow the same controls as other enterprise systems: 4. Audit and Monitoring Layer Capture complete interaction records: 5. Governance and Policy Layer Define rules governing AI behavior: Quick Compliance Readiness Checklist Use this 10-point rubric to evaluate your AI environment. Score 1 point for each “Yes.” Score Interpretation 8–10 → Compliance-ready architecture5–7 → Moderate risk0–4 → High compliance exposure Actionable takeaway:Compliance readiness depends far more
On-Premise AI vs Private Cloud AI: Data Protection Guide
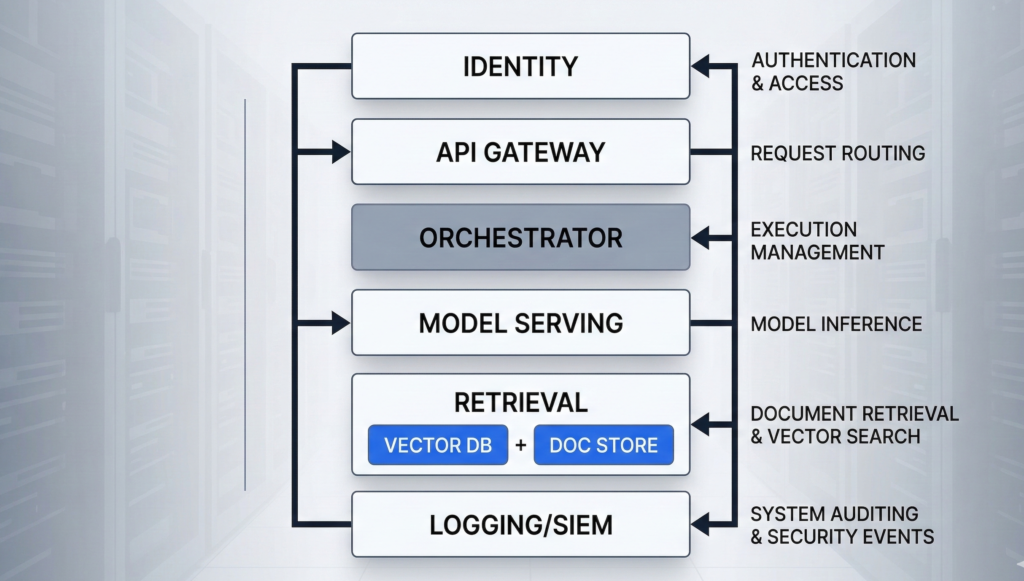
A procurement team wants “AI in 90 days.” Legal asks where prompts are stored. Security asks who can retrieve embeddings. Compliance asks for retention, audit logs, and data residency. And your infrastructure team asks the question that actually decides everything: on-premise AI vs private cloud AI — which deployment model keeps company data under control when the system is under pressure? Most articles answer this like it’s a hosting preference. It isn’t. Deployment model changes your trust boundaries: where data can flow, who can administer it, what gets logged, and how quickly you can prove compliance when an incident or audit hits. This guide breaks the decision down the way infrastructure teams actually evaluate it: architecture, identity and access, key management, observability, regulatory scope, operational maturity, and failure modes. You’ll get a practical rubric you can use in an internal review, plus a checklist you can hand to your security and compliance stakeholders without triggering a week of back-and-forth. H2: What “protects data” actually means in enterprise AI When leaders ask which option “protects data,” they’re usually bundling several requirements into one word. Separate them, and the tradeoffs become concrete. Data protection in enterprise AI typically means: The misconception: people treat “cloud” as inherently less secure or “on-prem” as inherently safer. In practice, the riskiest systems are the ones with unclear boundaries: shared admin accounts, undocumented egress, no prompt/output logging policy, and no change control over prompts and retrieval. Actionable takeaway: Before you compare AI deployment models, write a one-page “data protection definition” for your program: the data types involved, allowed storage forms, required logs, retention windows, and who must approve changes. If you can’t define this, no deployment model will save you. H2: On-premise AI architecture — what you control (and what you inherit) On-premise AI usually means the core components run in your own data center or dedicated facilities: model serving (GPU/CPU), retrieval (vector database + document store), orchestration, identity integration, logging, and monitoring. The real benefit is control over the full stack—especially the last mile of data handling. What on-prem gives you: What on-prem makes you responsible for: The under-discussed failure mode: “on-prem” systems often drift into security debt because upgrades are hard, GPU stacks are fragile, and teams postpone patches. That creates a slow-moving risk that is easy to ignore until the first incident. Actionable takeaway: If you choose on-prem, require an operational plan upfront: patch cadence, image hardening baseline, log retention, admin access model, and a quarterly restore test. Treat it like a product, not a server rack. H2: Private cloud AI explained — isolation, controls, and the real trust boundary Private cloud AI isn’t “public cloud with a nicer name.” The security posture depends on whether you’re getting a logically isolated environment with private networking, hardened IAM, and auditable controls—or simply hosting workloads in a standard tenant with better marketing language. A strong private cloud deployment for enterprise AI commonly includes: Where private cloud often wins: operational rigor. Many organizations can enforce least privilege, collect logs, and roll out updates faster in cloud environments because the primitives are mature and integration patterns are standardized. Where it can lose: unclear administrative access paths. If your threat model includes powerful cloud admin roles, vendor support access, or misconfigured cross-account permissions, “private cloud” can still allow data exposure—just through different doors. The practical framing: private cloud reduces certain risks (drift, inconsistent logging, slow patching) and increases others (control plane dependency, cloud IAM complexity). Security becomes an IAM and governance discipline problem. Actionable takeaway: Ask one question early: “Can we prove—through logs and policy—that no human can access production prompts and retrieval data without an auditable break-glass event?” If the answer is vague, your private cloud is not yet “private” in the way compliance expects. H2: Compliance and audit readiness — evidence beats architecture slogans Regulated environments don’t reward good intentions. They reward evidence: documented controls, consistent enforcement, and audit trails that stand up to scrutiny. Whether you deploy on-prem or private cloud, auditors and internal risk teams usually want proof of: Where on-prem can be stronger: when regulations or internal policy require strict data locality and you need full control over storage, backups, and log retention with no external dependency. Where private cloud can be stronger: when your organization needs standardized evidence across environments—centralized logs, policy enforcement, and repeatable infrastructure builds that generate consistent artifacts. Common compliance trap: teams focus on where the model runs and ignore the surrounding data flows—CRM connectors, call recordings, transcription pipelines, analytics exports, and support tooling. Most “AI data leaks” happen in the integration layer, not inside the model. Actionable takeaway: Build your “audit evidence map” before buildout: for each control (access, change, retention, encryption), specify (1) where evidence is logged, (2) who reviews it, and (3) how long it’s retained. Choose the deployment model that makes this easiest to execute reliably. H2: Cost, scalability, and latency — the tradeoffs that quietly change risk Security decisions get reversed later when the system can’t meet real-world performance requirements. That’s why cost, scalability, and latency are not separate from data protection—they influence architecture decisions that determine where data ends up flowing. Latency (especially for voice AI): Scalability: Cost: The risk link: when teams can’t scale safely, they introduce shortcuts—public endpoints “temporarily,” shared admin accounts “for speed,” or exporting data to third-party tools “just to debug.” Those shortcuts become the real breach path. Actionable takeaway: Treat performance constraints as security requirements. Document concurrency expectations, acceptable latency thresholds, and data flow boundaries under load. Then choose the deployment model that meets those requirements without “temporary” exceptions. H2: Hybrid AI models for regulated industries — isolate what must be isolated Many enterprise environments don’t have a single “right” answer because different data classes have different constraints. Hybrid deployment solves this by placing the strictest data inside the strictest boundary, while keeping the rest of the system operationally efficient. A common hybrid pattern looks like this: Why hybrid works: it aligns “where the data lives” with “how